This document once was a chapter within the Developers' Guide. We now converted this chapter into a stand alone document because the topic “security” is too important for being mentioned on “page 258” of some general documentation. ...and we added much more information.
This document is a “must-read” for:
CaptainCasa developers
software security architects
persons which are involved in security audits
This guide concentrates on these aspects of security which are technical aspects.
Within an application there are a couple of aspects in addition that are application-related (e.g. authority management). These aspects are not treated in this document.
This is a “living” document. CaptainCasa actively takes part in security audits of applications that use CaptainCasa Enterprise Client as front-end architecture. Results of these audits are constantly added to this document.
All traffic between browser and server might go through infrastructures that you are not really aware of! Consequence: sending data without encryption and sending data without any technical authentication of the server is a 100% “no-go”!
Do never use “http://” in production environments. Always go through “https://”!
A “.risc” URL starts the corresponding page on server side.
Typically you want to define dedicated entrance pages into your application system – and you do not want to allow the user to “free-style” open any page that you provide.
To check this there is an own mechanism that is part of the CaptainCasa server runtime. There is an interface “IStartPageChecker”:
package org.eclnt.jsfserver.starter;
import javax.servlet.http.HttpServletRequest;
public interface IStartPageChecker
{
public boolean checkIfPageCanBeDirectlyStarted(HttpServletRequest startRequest, String page);
}
Every time a “.risc” page is started then this interface called.
There is a default implementation “DefaultStartPageChecker” that is always active.
This default implementation is checking for definitions inside the system.xml configuration file:
<system>
<riscstarter
...
>
...
<allowstart page="/abc/*"/>
<allowstart page="/*/index.*"/>
<allowstart page="/xxx/yyy.jsp"/>
...
<excludestart page="/abc/*"/>
<excludestart page="/*/index.*"/>
<excludestart page="/xxx/yyy.jsp"/>
...
</riscstarter>
</system>
Here you have two options:
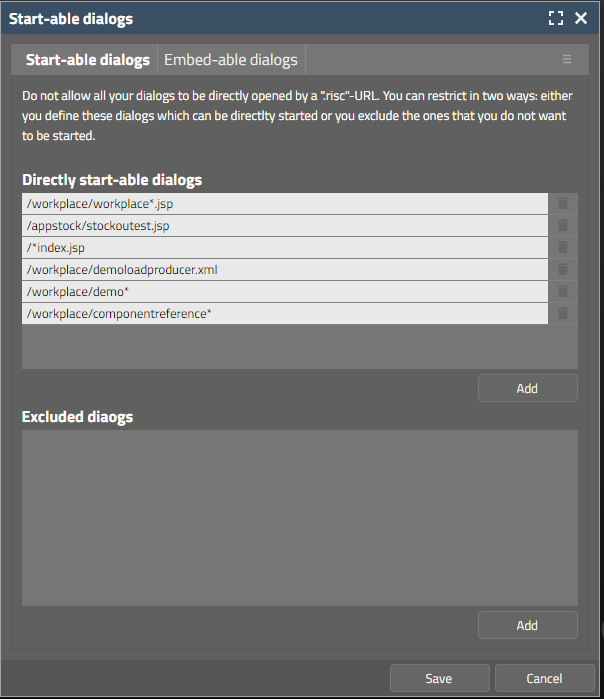
You may explicitly define these pages which you allow the user to directly open.
You may explicitly define these pages which you do not allow the user to directly open.
Of course: adding one “allowstart” definition will automatically over-rule all “excludestart” definitions! So you need to either do “allowstart” definitions or “excludestart” definitions – doing both does not make sense.
You can use the wildcard characters.
Please pay attention:
The default implementation is not activated when accessing the system with “http://localhost”-calls. - Reason: for testing during development you need to access pages directly.
If you want during development to test, if a page can be accessed in “non-development “-mode you need to add the parameter “ccprodmode=true” to the .risc URL.
If you want to set up some own implementation of “IStartPageChecker” then you can do so – we recommend to extend your implementation from CaptainCasa's default implementation.
You need to register your implementation in system.xml:
<system>
...
<riscstarter
...
startpagecheckerclassname="<class name of IStartPageChecker implementation>"
...
>
...
...
</riscstarter>
</system>
By default a page (opened by a “.risc” URL) is not embed-able into IFRAMEs for security reasons. This is independent from the definition of entrance-pages which is explained in the previous part of this chapter.
The embedding of pages is ruled via http-header-attribute “x-frame-options”. This attribute can be explicitly defined within the CaptainCasa processing.
In system.xml there are the following configuration options:
<riscstarter
...
embedableasiframe="sameorigin"
...
<allowiframeembedding page="/workplace/demohelloworld.jsp"/>
<allowiframeembedding page="/*/index.*"/>
...
</riscstarter>
By the element “allowiframeembedding” you explicitly define these pages which can be integrated into other IFRAMEs. For these pages the “x-frame-options” attribute is not set at all – so anyone can embed them.
By attribute “embedableasiframe” you define what happens to pages that are not defined by element “allowiframembedding”. You can define as follows:
“true” – there are no restrictions: all pages can be embedded from any other page (“x-frame-options” not set)
“false”/”deny” - the pages cannot be embedded (“x-frame-options” set to “deny”)
“sameorigin” or no definition at all - page can be embedded into dialogs from the same root (the root being the server/port part of the URL). So if your application is started in “http://xxxx:yyyy/...yourApplicationPath...” then only pages sharing the same root (“http://xxxx:yyyy”) can embed.
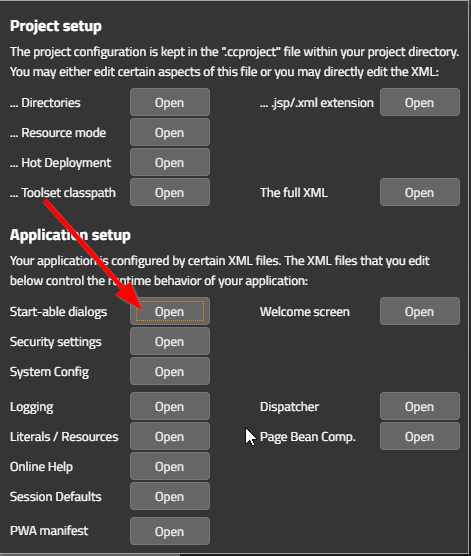
The tools of CaptainCasa allow to apply the definitions in system.xml in a more comfortable way than direct XML editing. Calling “start-able dialogs”...
...will show up a subsequent dialog, in which you can define the start-able and embed-able dialogs:
All data of a user session is part of an normal http-session on server-side. The browser client passes the session-id with every call to the server, so that the server knows which data is addressed.
By accessing the session-id attackers can try to get into the session from an other browser (or program acting as browser). As consequence the session-id either needs to be part of the encrypted communication – or if not, then there must be additional functions in place to ensure that session-access from outside is not possible.
There are two areas of functions that are applied in this area:
(A) Hiding the session-id in all visible communication content
It has to me made sure that the session-id is not visible to any system that is involved in the communication between the browser and the server. The session-id must be part of the encrypted message content as consequence.
(B) In case of hijacked session-id: making it difficult to continue or take over the session on a different device.
Despite hiding the session-id in all communication it can still be hijacked in a very classical way: someone gets direct access to the browser, opens up the developer mode and reads e.g. the cookie information.
As consequence as much as possible information about the physical browser client has to be collected and kept with the server-side session. Every request into the session needs to be checked if the information coming with the request is the same as the one stored in the session. - Example: part of each http-request is the information about the software version of the browser. Starting a session on a Firefox browser and then suddenly continuing the session on a Chrome-browser would be some indicator that an attacker tries to take over.
There are two types of session management (see chapter “Session Management” within the Developers' Guide):
URL-based: the session-id (“jsessionid”) is part of all calls that are communicated between the browser and the server. Each URL that is referring to the session includes the session-id.
Example:
https://xxx.yyy.com/appxyz/abc.def;jsessionid=4711
COOKIE-based: the session-id is transferred as a “jsessionid”-cookie. Cookies are always part of the encrypted content of the communication. This means: hijacking is not possible by observing the https network traffic.
In case of using the URL-based session management, the session-id is directly “steal-able”, because it is part of the URL. The URL itself is obviously not part of the https encryption – because it is the central address that defines the target of the communication. In other words: it is the information which is written onto the “envelope” of what is sent and needs to be seen by all communication parts that send the “envelope” across the network.
This means: attackers can directly read the session-id by observing the https-network traffic.
And this also means: some additional function is required to ensure that sessions, even if knowing their session-id, cannot be hijacked.
The solution is quite simple: in addition to the session-id that is part of the URL, an additional “session-security-id” is communicated – but this time not as part of the URL, but as Cookie.
With the first contact of a browser to a CaptainCasa session, the server will include a cookie in the response to the browser, that contains a secure-randomly generated content. The value of this content is stored within the http-session on server-side.
From now on any request from the browser to the server that requires session-related information first is checked if the request contains the cookie-value and if it is the same that is managed within the server-side session.
In short words: a request without this correct cookie will not be accepted.
The cookie value is protected in the following way:
Cookie values are part of the encrypted payload of a request. There is no way for a man in the middle to find out the value.
The cookie itself is marked with “httpOnly” - so it's not possible to access the value through JavaScript-injection.
The value is never output or logged on server-side.
Within the http session the value is not kept as plain string but there is an hiding object in front, so that it is not output as String in monitoring tools. Example: the Tomcat-manager application is able to list all data that is directly bound to the http-session.
The filter "SecurityFilterGeneral” is the one that exactly performs this management of an additional session-security-id. The name of the cookie holding this id is “”.
Filter class
org.eclnt.jsfserver.util.SecurityFilterGeneral
Technical infos
Name of cookie: ccclientcheckidgeneral
Short description
Adds a security id as cookie to the https communication and ensures that this id is in sync with the id that is kept inside the server-side http-session
Relevance
URL-based session management
Very important! - Here the session-id is published as part of the URL, so some additional security-id must be part of the encrypted content of the communication
COOKIE-based session management
Not important, can be switched off. - Here the http-session-id already inside the encrypted part of the communication. An additional security-id is not adding any improvement.
Switching off is done by the following definition in system.xml:
<system>
...
<filterconfiguration
active="false"
classname="org.eclnt.jsfserver.util.SecurityFilterGeneral"/>
...
</system>
The Java-Swing client does not manage cookies, so the “SecurityFilterGeneral” is switched off for messages originating from this client. (The information of the client type is also inside the encrypted part of the communication.) The Java-Swing client can only be used with URL-encoding of the session id.
For this client there is a similar mechanism in place, that adds a security id to the communication, this time not as cookie but as extra parameter that is added to the http-post communication.
All internal communication between the Java-Swing client and the server is based on http-post communication – and as result is secured for session-hijacking. - Calls to external systems by http-get are not secured. Concrete scenario: the Java-Swing client can open up a browser by passing a URL. This URL is processed as http-get by the browser.
Filter class
org.eclnt.jsfserver.util.SecurityFilter
Short description
Adds a security id as http-post parameter to all http-post communication and ensures that this id is in sync with the id that is kept inside the server-side http-session
The name of the post parameter is “ccclientcheckid”
Relevance
Using Java-Swing client
Very important! Must not be switched off.
Using RISC-HTML client
Not relevant, “SecurityFilterGeneral” (see previous chapter) is the better option because it not only secures the http-post communication but all communication from the browser side
The principles already were discussed in the introduction of this chapter: each request from a browser includes information about the browser itself. This information is collected and stored in the server-side session. Once a call into the session is not including exactly the same client-information as before must end in an error to prevent the take over of the session. - Sometimes people refer to a “fingerprint” that is sent with every request and that is always checked on server side against the “fingerprint” that initiated a session.
The browser does not send too much “fingerprint”-information, for good reason: in normal Internet-scenarios you do not want the server to exactly know who your are – otherwise it would be too easy to store information about you. So there is no MAC-address or equivalent that can be used...
Nevertheless: this information which comes from the browser side need to be used for checking.
Filter class
org.eclnt.jsfserver.util.SecurityFilterRemoteAddress
Short description
Checks the information about the browser which is part of every request and compares against information that was stored when initiating the session
The information that is checked includes
The so called “remote address”
Information in the header attribute “x-forwarded-for”. In case of several routers there might be a comma-separate list of addresses in this field – here the first address is used which is the one that is closest to the user's browser
Information in the header attribute “user-agent”
Relevance
Is not a strong protection due to limited information passed by the browser – but at least ensures that “stupid attacks” are failing
Known scenarios in which the filter can not be applied
In some scenarios ip-addresses of involved parties may change during runtime, in this case the filter indicates a take-over of a session without being attacked.
When the filter “SecurityFilterRemoteAddress” detects some problem then it throws some error that is logged into the CaptainCasa log file:
java.lang.Error: Client that sends the request is not the one that created the session.
You should analyze the error and check the addition information in the CaptainCasa log file. The detailed information is output in front of the error message:
Client that sends the request is not the one that created the session. Aborting security check with error. ...URL...
Session information: ...
Request information: ...
...Stacktrace...
In the log you see the client information that is stored with the session and you can compare against the one that is coming with the request. You can see the three items which make the client information (remote address, x-forwarded-for, user-agent) separated by a slash “/” and you can check if there is a good reason for the difference between the session-information (originating from the first request opening the session) and the information for the current request.
If there is a good reason:
Tell CaptainCasa about. Maybe we should include this reason into the rules of the default filter processing.
Check if to extend the filter by some own rules: the filter “SecurityFilterRemoteAddress” is written a way so that it can be easily extended.
Like any other filter you can switch off the filter by a definition in system.xml:
<system>
...
<filterconfiguration
active="false"
classname="org.eclnt.jsfserver.util.SecurityFilterRemoteAddress"/>
...
</system>
There are security scenarios in which you have to explicitly avoid that the network activity of a certain http-request-processing is recorded and replayed somewhere after-wards.
To avoid this, CaptainCasa introduced a component CLIENTSECID that is bound to a server side object of type CLIENTSECIDBinding. The component requests from the CLIENTSECIDBinding a new id within each request-response processing on server side. This id is sent to the client side and re-sent to the server with the next request.
On server side a request is checked if the id that is received corresponds to the last id that was sent to the client. Then a new id is generated and sent with the response to the client.
The ids that are generated are random ids, that are not predictable to anyone trying to replay a certain recorded http-sequence against your server.
The CLIENTSECID component (arranged below the component BEANPROCESSING) should be placed on the outest page of your scenario, i.e. the one that is your starting page.
With CaptainCasa no direct HTML content is sent from the server to the client side. The server transfers component data as XML to the client, which is there used to update corresponding components.
All CaptainCasa client side components that transfer data from the server into a text that is shown within the browser are programmed to avoid JavaScript injection. By default the HTML that is inserted is escaped – this means, that any HTML-character is converted into a safe variant before being passed into the the text of the corresponding HTML-element:
var result = value.replace(/&/g, "&")
.replace(/>/g, ">")
.replace(/</g, "<")
.replace(/"/g, """)
.replace(/'/g, "'")
.replace(/\//g, "/");
This means: if e.g. assigning a BUTTON-TEXT with the value “Hal<b>lo</b>”, then the text that is shown in the button is not “Hallo” (i.e. “Hallo” with the “lo” being output with bold font weight) – but the text that is shown in the button is “Hal<b>lo</b>”.
In some few cases and for dedicated controls only, the corresponding controls accept meaningful HTML code – this means the HTML is inserted “as is”, without escaping. These cases are:
TEXTPANE being used with content type “text/html”
TEXTWITHLINKS
SMARTLABEL
TREENODE with smart text being switched to “true”
SIMPLEHTMLEDITOR
In these cases the HTML is explicitly sanitized by default on client side before being passed into the HTML element. This sanitizing is done by using the corresponding algorithms from the Google-caja project – using an HTML4-based white list of allowed tags and attributes.
This algorithm is a quite restrictive one – and e.g. also removes images. But it is adequate to transfer formatted text content properly.
All the components provide an attribute AVOIDSANITIZING. If you set to “true” then the client side sanitizing is not executed and the text that comes from your application is directly inserted into the corresponding HTML-element.
When using this attribute then you explicitly take over for passing correct HTML content! This means:
Only render text content that you trust.
In case of assembling the HTML out of e.g. some template that is filled with application data: use encoding functions to do the “escaping” of special characters when adding text into an HTML document.
Even though the base of CaptainCasa (as described in “General processing” at the begin of this chapter) is the communication of XML content between the client-side and the server, there are some places where direct browser content is created.
Creation of starter page (“.risc”-page)
Creation of images (.svg, .png)
HTML-pages or PDF-pages that are created by your application (e.g. as reporting output) and that are made available as URL by “BufferedContentMgr” to “TempFileMgr”.
When calling a “.risc”-URL in the browser then the HTML-page that is responded to the browser is exactly the one that brings the JavaScript-Single-Page-Application into the browser that form the CaptainCasa client processing.
Servlet class
org.eclnt.jsfserver.starter.RISCStarter
Short description
Create the starter page which includes the JavaScript base for starting the CaptainCasa client processing as Single Page Application
Security-relevant information
The page is created by a server-side template that is enriched by parameters.
Apart of dedicated parameters (e.g. title of page), all parameters are part of server-side data (template files, system.xml configuration) and cannot be overruled by request parameters
These dedicated parameters coming from “outside” (e.g. from “.risc”-request itself) are
...encoded using ESAPI-functions if they are transferred into the HTML document (e.g. “title” attribute)
...explicitly checked to be valid before they are processed (e.g. “ccstyle” attribute)
Certain images are created by CaptainCasa dynamically. Examples:
When using flat SVG icons then (e.g. “/icons/svg/save.svg”) then you can create a colored instance with a certain size by calling a corresponding servlet processing (e.g. “/icons.svg.save._800000.16x16.ccsvg”. The server side will take the original SVG and will create a dynamically created response in which the style of the SVG is updated.
When using SVG image you can create a PNG version out of the SVG image.
You can create an image for a certain text with a certain font size (which is a compatibility function for some BGPAINT commands).
Servlet class
org.eclnt.jsfserver.util.DynamicImageServlet
Short description
Dynamically creates images
Security-relevant information
For images created as SVG
Existing, server-side SVG images are used as template – which must directly reside in the resources of the application (i.e. which are not e.g. accessed by URL). Input parameters for replacing e.g. the color or the size are explicitly checked if they represent color/size values.
For images created as PNG
Input parameters are checked if they are reasonable.
Example: a creation of text images with a font size > 100 is not allowed in order to avoid a potential out-of-memory when creating the images on server-side.
An application can create content that either should be downloaded by the user or that should be displayed in a new browser tab. Example: an application might create some HTML or PDF report.
CaptainCasa provides two mechanisms to publish dynamic content as URL:
“BufferedContent” - Here the content is directly created by some application program when it is requested by a corresponding URL.
“TempFileManager” - Here the content is created by the application and written into a temporary location of the server (servlet-temp-directory). The browser can pick up the content with a corresponding URL.
servlet class
org.eclnt.jsfserver.bufferedcontent.BufferedContentServlet
org.eclnt.jsfserver.util.tempfile.TempFileAccessServlet
Short description
Access to application content by URL which is dynamically created
...through some buffer information kept in memory
...through a temporary file that is written into the temp directory of the servlet container
Security-relevant information
The content that is produced within one application session can only be accessed within this session. i.e. it cannot be accessed from other browsers.
Each content is receiving a secure-randomly generated id which is core part of the URL to access the content.
The content is removed on server-side either directly by the application or by the CaptainCasa runtime at the end of a session.
Risk
The purpose of both of the servlets is to make content of the application available as URL, so that the content can be shown inside the browser (or downloaded).
Both servlets explicitly do not know the content – and do not take part in the creation of the content. They treat the content as black box.
Applications using these functions need to ensure that the content is properly created and that rules e.g. for avoiding JavaScript injection are correctly applied.
In case of some sever application error situation it is super-nice for developers to directly see a browser page that e.g. list the full stack trace of the error.
But: this opens up the risk that internal information could be now published to the end user which might be usable to prepare some attack.
Examples:
Internal information such as user names, database names, etc. could be part of the error messages
The architecture of the application might be visible, e.g. when showing a stack trace of a database error then the information might include the levels of software which are used to access the database.
Consequence: even though it make the process of analyzing errors more complex: detail of the error needs to be hidden in front of the user.
Filter class
org.eclnt.jsfserver.util.ErrorAnonymizerFilter
Short description
Catches any information about errors happening “behind” the filter, stores them as error-message in the CaptainCasa logging and provides a general error message to the end user
Please note: we are not talking about normal applications errors here (which are output into the status bar of the application)! These are the severe system errors that might occur during runtime.
Relevance
Should be applied.
Why should you take care of cache at all? Because the cache of the browser is something which is not protected to be abused. Imagine you are in an Internet cafe and you watch some nice PDF report that is generated by your business application. If this report is cached by the browser then the next user of the computer could open the cache and check what you left as information...
The main data communication inside CaptainCasa between the browser client and the server is based on a POST-processing – which by default is not cache-able.
Nevertheless (and after the experience of security audits...) we define a “no-cache/no-store” statement in the POST-responses... ;-)
Special resources such as JavaScript and CSS-files are explicitly cached on client side, so that they do not have to be loaded every time you start the application. CaptainCasa appends a version-stamp to all the requests that are loading “.js” and “.css” files. In case the version of CaptainCasa changes (which means: updated “.js” files), the new versions will be automatically read because the URL now has a different version stamp.
All content that is dynamically created (e.g. PDF created via BufferedContentMgr or by TempFileManager) is defined as being not-cache-able.
General resources of a web application (e.g. PNG images, SVG files, ...) are by default not explicitly treated. CaptainCasa provides filters which you might use to easily define...
...that a resource should not be cached on client side
...that a resource should be cached as long as possible on client side.
Filter class
org.eclnt.jsfserver.util.NoCacheNoStoreFilter
Short description
Set header attributes of http-response so that browser does not cache the content of the response
Relevance
Must be applied for all content containing application data (e.g. reports).
Without applying this filter, content might be kept in the cache of the browser (i.e. stored in the local file system) also after the user leaving the browser session.
Filter class
org.eclnt.jsfserver.util.CacheFilter
Short description
Set header attributes of http-response so that browser caches the response for very long time
Relevance
Improves loading time of your application and reduces network-traffic.
Must not be applied for content that contains application content.
You may extend both filters to include by updating the “system.xml” configuration:
...
<filterconfiguration
active="true"
classname="org.eclnt.jsfserver.util.NoCacheNoStoreFilter"
additionalmappings="...mapping...;...mapping...;...mapping..."
/>
...
The “mapping” definition is the one that is directly passed into the filter configuration. It is the same mapping that you would define in “web.xml” files and allows the positioning of a “*” either at the end or at the beginning. Examples:
“/xxx/*”
*.xxx”
There are certain header-attributes of http-responses that affect the security because they tell the browser client what it is allowed to do in the context of the loaded content.
The ones that are currently treated by CaptainCasa's runtime are:
“x-xss-protection” is by default set to “1; mode=block”
“x-content-type-options” is by default set to “nosniff”
“referrer-policy” is by default set to “same-origin”
“content-security-policy” is by default set to “default-src 'self' data: 'unsafe-inline' 'unsafe-eval'; img-src * data:”
We do not explain the meaning of each of the http-header parameters in this documentation. Please refer to publicly available information.
The filter is applied to all extensions that are the ones to be directly loaded within the browser:
“.risc” requests
“.html” requests
Filter class
org.eclnt.jsfserver.util.HttpHeaderAttributesForPagesFilter
Short description
The filter sets certain header-attributes of http-responses
“x-xss-protection”
“x-content-type-options”
“referrer-policy”
“content-security-policy”
The filter by default returns values that represent “best practice” values but can be customized individually
Relevance
Especially the “content-security-policy” is a useful feature to ensure that the browser does only access information that you allow the browser to access.
The “content-security-policy” must be explicitly customized when accessing resources from your application that are not part of your application.
Example: if you want to embed a certain HTML page as iframe into you application which is coming from a different server than the own one, then you have to add the name of this server to the “content-security-policy” - otherwise the browser will tell you that you are not allowed to access this content.
You may configure the values that are set by some configuration in “system.xml”:
...
<httpheaderattributesforpages
x-xss-protection="1; mode=block"
x-content-type-options="nosniff"
content-security-policy="default-src 'self' data: 'unsafe-inline' 'unsafe-eval'; img-src * data:"
referrer-policy="no-referrer"
/>
...
In the definition of the “httpheaderattributesforpages” element you only need to define these attributes that you want to explicitly control. Example: if you only want to update the content-security-policy, then you may define:
...
<httpheaderattributesforpages
content-security-policy="...your definition..."
/>
...
If explicitly defining an empty string (“”) then the http-header field is not set by the the filter. Example:
...
<httpheaderattributesforpages
content-security-policy=""
/>
...
There are certain areas in which resources can potentially be accessed by class loader:
As developer you can decide if you want to store layout (.jsp/.xml files), images and other web resources inside the normal web content or within the sources.
SVG Images can be accessed e.g. by a “.ccsvg” exension, by which you can pass the size and the coloring of the image as part of the URL.
You can explicitly load any resource by using “.ccclresource” extension.
Why does CaptainCasa allow access to resources that are loaded by class loader at all?
It's the possibility to distribute applications and components as self-containing .jar files. These .jar files not only contain the Java-programs (.class files) but also contain all the resources that these programs require for their processing.
Example: a component that requires some button images, needs to make these images available in way that the browser can access – i.e. by calling a URL. So a URL not only targets the “webcontent” of an application but also the resources that are part of the application's .jar file.
Of course your .jar file (and the resources you keep in the /classes directory) may contain a lot of information that must not be directly accessed by a URL!
So there must be a careful selection of resources that can directly be accessed by the browser.
Only resources with an extension can be loaded that are part of white list of extensions. The extensions that by default are allowed to be accessed are:
bmp
css
eot
gif
giff
htm
html
jpg
jpeg
js
js.map
png
svg
tif
tiff
ttf
txt
woff
woff2
Every time CaptainCasa accesses a resource by class loader then interfaces of type “IResourceSeecurityChecker” are called:
public interface IResourceSecurityChecker
{
/**
* @param path
* Access path into the classloader. String starting with "/" e.g.
* "/com/xyz/resources/whatever.png"
*
* @return
* true ==> access is allowed, false ==> access is not allowed,
* null ==> path not relevant for this checker
*/
public Boolean checkClassLoaderPathForOutsideUsage(String path);
}
Here the resources access can be explicitly checked by the application.
Implementations of the interface can be registered by either registering in system.xml configuration file...
<system>
...
<resourcesecuritychecker name="...className..."/>
...
</system>
...or by directly registering by using the API:
ResourceSecurity.addResourceSecurityChecker(...);
The server side processing of CaptainCasa Enterprise Client provides some extra functions in order to check any outgoing or ingoing values.
The following interface is processed for each request and for each response:
package org.eclnt.jsfserver.injection;
public interface ICheckInboundAndOutboundValues
{
public String checkInboundValue(String tagName,
String attributeName, String value);
public String checkOutboundValue(String tagName,
String attributeName, String value);
}
The implementation of the interface is registered within the sytem.xml configuration file (webcontent/eclntjsfserver/config/server.xml):
<system>
...
<checkinboundandoutboundvalues name="...className..."/>
...
</system>
At runtime an instance of the class is created by using a constructor without parameters.
Any client side value (e.g. a field content) that is passed into the server side processing can be updated by implementing the method “checkInboundValue()”.
Any value (e.g. value behind an expression) that is sent to the client side as part of the response may be updated by implementing the method “checkOutboundValue()”.
All file access within the CaptainCasa server processing is done through the class “FileManager” (org.eclnt.util.file.FileManager). The class is a public class so it may also be used by your application.
Inside the FileManager there is the possibility to restrict the access to the file system. There are two corresponding methods:
FileManager.addAllowedRootDirectoryReadWrite(...directoryName...)
FileManager.addAllowedRootDirectoryRead(...directoryName...)
By default the FileManager starts without any restrictions, so it has full access to the file system. After calling one of the methods, the FileManager will run in restricted mode.
You may define restrictions in addition by using the configuration file “system.xml” (<webcontent>/eclntjsfserver/config/system.xml). Example:
<system>
...
...
<filemanagerreadaccess directory="${servletwebapp}"/>
<filemanagerwriteaccess directory="${temp}"/>
<filemanagerwriteaccess directory="${servlettemp}"/>
<filemanagerreadaccess directory="c:/bmu_jtc"/>
<filemanagerreadaccess directory="c:/temp"/>
...
...
</system>
There are some predefined variables, please check the documentation in the template file (system.xml_template) for detailed information.
If restricting the access then make sure that the following directories are always added, because CaptainCasa requires access:
<filemanagerreadaccess directory="${servletwebapp}"/>
<filemanagerwriteaccess directory="${temp}"/>
<filemanagerwriteaccess directory="${servlettemp}"/>
By using the HTML element “iframe” you can embed one page into another page. There is a certain risk involved, named “clickjacking”. Basically the embedding page can try to overlay the content of the embedded page without showing to the user and by this e.g. can capture field input.
As consequence an HTML page needs to control the scenarios, in which it wants to be embedded into other pages – or not. This is controlled by the http header parameter “X-Frame-Options”.
CaptainCasa by default (from 20210628 on) sets the parameter to value “sameorigin” - which means: all pages that are running on the same domain can embed.
You can explicitly control the value of the parameter by configuring the system.xml file. The valid values are described within the documentation inside the template file:
<system>
...
...
<!--
*************************************************************************
Configuration of RISCStarter - the servlet that is responding on .risc
request.
...
...
embedableasiframe: default "sameorigin"; completely switch off by value
"deny" or "false"; allow embedding by value "true".
...
...
*************************************************************************
-->
<riscstarter
...
embedableasiframe="sameorigin"
...
/>
...
...
</system>
On server side the similar rules have to be applied than the ones that need to be applied for avoiding client-side JavaScript injection – of course with different scripting languages
Every place inside your application that is executing dynamically assembled script is dangerous! Reason: an attacker might try to define input data in a way that it implicitly contains scripting statements that are executed when the full script is assembled and run.
The most prominent example typically is “SQL injection”.
When assembling an SQL out of input data...
String sql = “SELECT * FROM PERSONS WHERE NAME='” + name + ”'”;
...then “nice” users might try to input the following input as name:
%' AND SALARY>1000000 AND TOWN='Berlin
The result which will now be assembled at runtime is:
SELECT * FROM PERSONS WHERE NAME='%' AND SALARY>1000000 AND TOWN='Berlin'
Luckily the solution is very simple: never assemble SQL strings directly. Always use so called “PreparedStatements”, so that you write:
String sql = “SELECT * FROM PERSONS WHERE NAME=?”;
PreparedStatement ps = connection.prepareStatement(sql);
ps.setString(1,name);
Prepared statements will never mix in data into the script – they explicitly separate one from the other.
There are a couple of persistence frameworks (Hibernate, etc.) that actually hide the SQL processing in front of the user. These frameworks internally are built on prepared statements typically – but better do a check!
...CaptainCasa also provides a super-simple and efficient persistence framework in its “CCEE-addons” package. Of course it internally is based on prepared statements.
When the client side JavaScript processing renders an image (e.g. IMAGE component itself, or: BUTTON-IMAGE) and when the size of the image is not explicitly set, then the size of the image is calculated by a server-side function, which is accessed through the servlet “ImageSizeServlet”.
The default operations are as follows:
The browser renders an image “/images/xyz.png”
The browser asks the ImageSizeServlet about the size of the image and sends a correpsonding request
The ImageSizeServlet reads and analyses the image and sends back the image size as string, e.g. “100;50” for 100 pixels of width and 50 pixels of height.
(Of course result information is buffered both on client and on server-side.)
By default image definitions are links to images that are part of the web application. This means the image URL is following the format “/aaa/bbb/ccc.jpg”, addressing the file “webcontent/aaa/bbb/ccc.jpg”.
But: you can also define images coming from external addresses. Example:
<t:button ... image=”http://captaincasa.org/wp-content/uploads/2020/06/stock2-768x505.png” .../>
In this case the server side reads the image from the specified address by http-request and retrieves the size from the image data. The image data itself is afterwards removed, only the width/height result are kept.
In order to prevent the server to load data from any server of the world wide web, there is an interface “IExtImageFilter”:
package org.eclnt.util.image;
/**
* Filter to check URLs to be loaded by image size processing of the server side
* image manager (class ServerImageManager). Here is is possible to find the size
* of some image from some external url. This url can be checked with this interface
* to prevent uncontrolled loading of images.
*/
public interface IExtImageFilter
{
/**
* @param url - url of the image that is analyzed
* @return - true: image is ok and can be loaded, false: image must not be loaded!
*/
public boolean checkURL(String url);
}
The default implementation that is used inside the ImageSizeServlet is:
package org.eclnt.util.image;
import org.eclnt.util.log.CLog;
/**
* Implementation of {@link IExtImageFilter} which blocks any type
* of loading external images. This is the default manager that is used
* and which avoids any external URL to be loaded.
*/
public class ExtImageFilterAllBlocked implements IExtImageFilter
{
public boolean checkURL(String url)
{
CLog.L.log(CLog.LL_WAR,"The external image was NOT read: " + url);
CLog.L.log(CLog.LL_WAR,"Reason: it is blocked by " + this.getClass().getName());
return false;
}
}
This default implementaion always returns “false” - which means: all image loading from the server-side to other servers is completely blocked.
You need to add some own implementation, in order to open up this mechanism. Your implementation needs to be registered in the “eclntjsfserver/config/system.xml” conifguration file:
<!--
*************************************************************************
Server image manager.
*************************************************************************
-->
<serverimagemanager
...
extimagefilterclassname="...implementation of class IExtImageFilter..."
...
/>